
머신러닝을 통한 자전거 대여 수요 예측: (2) Modeling
저번 EDA에 이어 자전거 대여 수요를 가장 잘 예측하는 모델을 찾아내고자 한다.
데이터는 Kaggle의 Bike Sharing Demand 대회 데이터를 이용했다.
상관 분석
correlation_matrix = df_train[['count', 'season', 'holiday', 'workingday', 'weather',
'temp', 'atemp', 'humidity', 'windspeed', 'year',
'month', 'day', 'hour']].corr()
plt.figure(figsize=(12, 8))
sns.heatmap(correlation_matrix, annot=True, fmt=".2f", cmap="coolwarm", cbar=True, square=True)
plt.title('Correlation Heatmap')
plt.tight_layout()
plt.show()
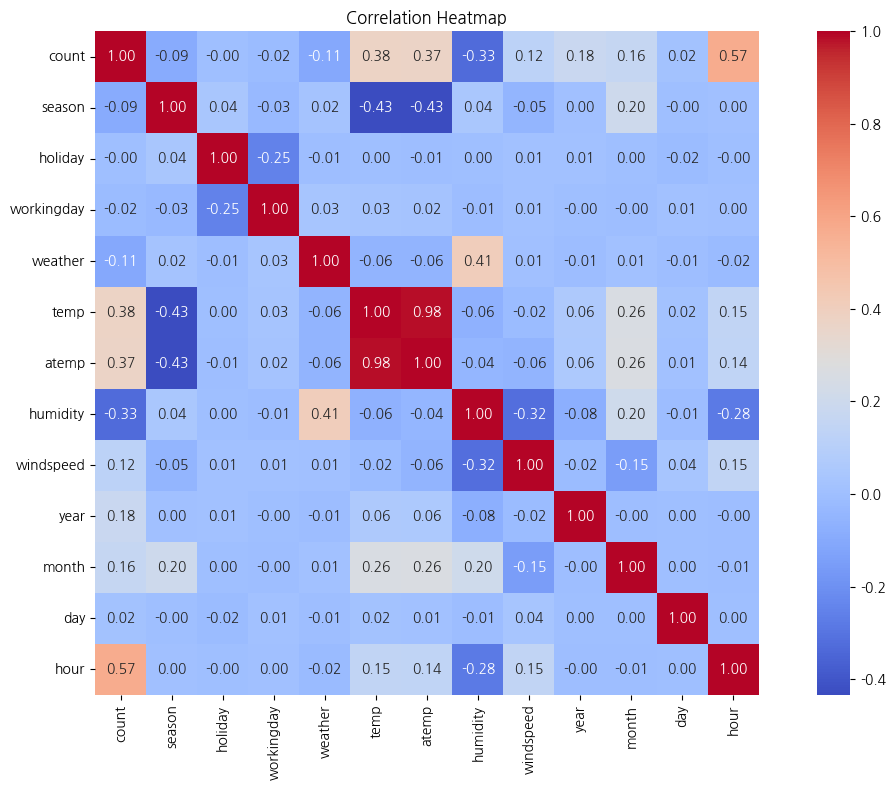
count변수와 상관계수가 가장 큰 변수는hour변수로, 상관계수는 0.57이다.
temp변수와atemp변수는 상관계수가 0.98로 매우 크므로, 독립변수로 사용 시 다중공선성 문제가 일어나지 않도록 두 변수 중 하나의 변수만 선택해 사용한다.
train 데이터와 test 데이터를 동일하게 전처리
# 데이터 불러오기
df_train = pd.read_csv('./src/train.csv')
df_test = pd.read_csv('./src/test.csv')
# 위아래로 합치기
df = pd.concat([df_train, df_test], ignore_index=True)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17379 entries, 0 to 17378
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 17379 non-null object
1 season 17379 non-null int64
2 holiday 17379 non-null int64
3 workingday 17379 non-null int64
4 weather 17379 non-null int64
5 temp 17379 non-null float64
6 atemp 17379 non-null float64
7 humidity 17379 non-null int64
8 windspeed 17379 non-null float64
9 casual 10886 non-null float64
10 registered 10886 non-null float64
11 count 10886 non-null float64
dtypes: float64(6), int64(5), object(1)
memory usage: 1.6+ MB
# string to datetime
df['datetime'] = pd.to_datetime(df['datetime'])
# year, month, day, hour, weekday 컬럼 생성
df['year'] = df['datetime'].dt.year
df['month'] = df['datetime'].dt.month
df['day'] = df['datetime'].dt.day
df['hour'] = df['datetime'].dt.hour
df['weekday'] = df['datetime'].dt.weekday
# season 변수 재정의
conditions = [
df['month'].isin([3, 4, 5]),
df['month'].isin([6, 7, 8]),
df['month'].isin([9, 10, 11]),
df['month'].isin([12, 1, 2])
]
choices = [1, 2, 3, 4]
df['season'] = np.select(conditions, choices)
# 카테고리형 변수로 형변환
categoricalFeatureNames = ["season", "holiday", "workingday", "weather",
"year", "month", "day", "hour", "weekday"]
for var in categoricalFeatureNames:
df[var] = df[var].astype("category")
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17379 entries, 0 to 17378
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 17379 non-null datetime64[ns]
1 season 17379 non-null category
2 holiday 17379 non-null category
3 workingday 17379 non-null category
4 weather 17379 non-null category
5 temp 17379 non-null float64
6 atemp 17379 non-null float64
7 humidity 17379 non-null int64
8 windspeed 17379 non-null float64
9 casual 10886 non-null float64
10 registered 10886 non-null float64
11 count 10886 non-null float64
12 year 17379 non-null category
13 month 17379 non-null category
14 day 17379 non-null category
15 hour 17379 non-null category
16 weekday 17379 non-null category
dtypes: category(9), datetime64[ns](1), float64(6), int64(1)
memory usage: 1.2 MB
독립변수와 종속변수 설정
동일하게 전처리하기 위해 합쳤던 데이터를 다시 원래대로 train 데이터와 test 데이터로 분할하였고, 모델링에 사용하기 위해 독립변수 데이터와 종속변수 데이터를 나누었다.
dataTrain = df[pd.notnull(df['count'])].sort_values(by=["datetime"])
dataTest = df[~pd.notnull(df['count'])].sort_values(by=["datetime"])
datetimecol = dataTest["datetime"]
yLabels = dataTrain["count"]
yLablesRegistered = dataTrain["registered"]
yLablesCasual = dataTrain["casual"]
dropFeatures = ["casual", "registered", "count", "datetime", "atemp"] # 다중공선성 문제로 atemp 변수도 제거
dataTrain = dataTrain.drop(dropFeatures, axis=1)
dataTest = dataTest.drop(dropFeatures, axis=1)
모델링 및 모델 평가
모델 평가는 Kaggle의 Bike Sharing Demand 대회 평가 기준처럼 RMSLE를 사용했다.
RMSLE는 큰 예측 오류를 더 큰 패널티로 처리하여 과대평가를 방지하고 예측 모델의 신뢰성을 높이는 데 도움을 주어, 자전거 대여 수요 예측과 같이 값이 다양한 문제에서 특히 유용하다.
RMSLE는 다음과 같이 계산된다.
여기서 $n$은 데이터 포인트의 수, $p_i$는 예측 값, $a_i$는 실제 값을 의미한다.
# rmsle 함수 정의
def rmsle(y, y_, convertExp=True):
if convertExp:
y = np.exp(y),
y_ = np.exp(y_)
log1 = np.nan_to_num(np.array([np.log(v + 1) for v in y]))
log2 = np.nan_to_num(np.array([np.log(v + 1) for v in y_]))
calc = (log1 - log2) ** 2
return np.sqrt(np.mean(calc))
Linear Regression
from sklearn.linear_model import LinearRegression
# Dummy Encoding으로 카테고리 데이터를 숫자로 변환
dataTrain_encoded = pd.get_dummies(dataTrain, drop_first=True)
# 모델 초기화
lModel = LinearRegression()
# 로그 변환한 대여 수로 학습
yLabelsLog = np.log1p(yLabels)
lModel.fit(X=dataTrain_encoded, y=yLabelsLog)
# 예측 및 RMSLE 계산
preds = lModel.predict(X=dataTrain_encoded)
print("RMSLE Value For Linear Regression:", rmsle(yLabelsLog, preds, True))
RMSLE Value For Linear Regression: 0.5534088153175948
Ridge Regression
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
# Ridge Regression
ridge_m_ = Ridge()
ridge_params_ = {'max_iter': [3000], 'alpha': [0.1, 0.2, 0.5, 1, 1.5, 2, 2.5, 3, 4, 5, 6, 10, 20]}
rmsle_scorer = metrics.make_scorer(rmsle, greater_is_better=False)
grid_ridge_m = GridSearchCV(ridge_m_, ridge_params_, scoring=rmsle_scorer, cv=5)
# 로그 변환된 대여 수로 학습
yLabelsLog = np.log1p(yLabels)
grid_ridge_m.fit(dataTrain_encoded, yLabelsLog)
# 예측 및 성능 평가
preds = grid_ridge_m.predict(dataTrain_encoded)
print("Best Parameters for Ridge Regression:", grid_ridge_m.best_params_)
print("RMSLE Value For Ridge Regression:", rmsle(yLabelsLog, preds, True))
Best Parameters for Ridge Regression: {'alpha': 1.5, 'max_iter': 3000}
RMSLE Value For Ridge Regression: 0.5535269799317817
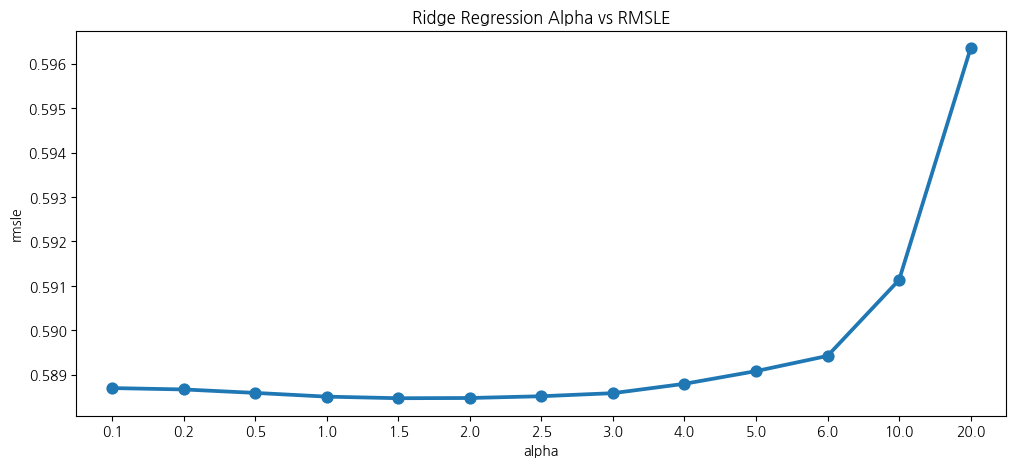
Grid Search를 이용해 Ridge Regression 모델이 가장 좋은 성능을 내는 최적의 alpha값을 1.5로 찾았다.
RMSLE 값은 Linear Regression보다 아주 조금 더 크게 나타난다.
# alpha 값에 따른 Ridge Regression 모델의 RMSLE 시각화
fig, ax = plt.subplots()
fig.set_size_inches(12, 5)
results = pd.DataFrame(grid_ridge_m.cv_results_)
results["alpha"] = results["param_alpha"]
results["rmsle"] = -results["mean_test_score"]
sns.pointplot(data=results, x="alpha", y="rmsle", ax=ax)
ax.set(title="Ridge Regression Alpha vs RMSLE")
plt.show()
Lasso Regression
from sklearn.linear_model import Lasso
# Lasso Regression
lasso_m_ = Lasso()
# alpha 값 생성 (1/alpha 형태로 생성)
alpha = 1 / np.array([0.1, 0.2, 0.5, 1, 1.5, 2, 2.5, 3, 4, 5, 6, 10, 20])
lasso_params_ = {'max_iter': [3000], 'alpha': alpha}
# GridSearchCV로 하이퍼파라미터 튜닝
grid_lasso_m = GridSearchCV(lasso_m_, lasso_params_, scoring=rmsle_scorer, cv=5)
# 로그 변환된 대여 수로 학습
grid_lasso_m.fit(dataTrain_encoded, yLabelsLog)
# 예측 및 성능 평가
preds = grid_lasso_m.predict(dataTrain_encoded)
print("Best Parameters for Lasso Regression:", grid_lasso_m.best_params_)
print("RMSLE Value For Lasso Regression:", rmsle(yLabelsLog, preds, True))
Best Parameters for Lasso Regression: {'alpha': np.float64(0.05), 'max_iter': 3000}
RMSLE Value For Lasso Regression: 0.9750827231906595
Lasso Regression의 경우 Ridge Regression과 달리 변수의 계수를 0으로 만들어 중요하지 않은 변수를 제거할 수 있다.
하지만 이러한 특징으로 인해 하이퍼파라미터인 alpha값을 너무 크게 설정하면 중요한 변수도 제거가 이루어질 수 있다.
따라서 Lasso의 경우 Grid Search를 이용할 때 실험할 alpha값들을 Ridge보다 작게(보수적으로) 준다.
Grid Search를 이용해 Lasso Regression 모델이 가장 좋은 성능을 내는 최적의 alpha값을 0.05로 찾았다.
RMSLE 값은 Linear Regression과 Ridge Regression보다 더 크게 나타난다.
Random Forest Regression
from sklearn.ensemble import RandomForestRegressor
# Random Forest Regression
rfModel = RandomForestRegressor(n_estimators=100, random_state=42)
# 학습
rfModel.fit(dataTrain_encoded, yLabelsLog)
# 예측 및 성능 평가
preds = rfModel.predict(dataTrain_encoded)
print("RMSLE Value For Random Forest:", rmsle(yLabelsLog, preds, True))
RMSLE Value For Random Forest: 0.15071404103191188
RMSLE 값이 앞의 모델들보다 현저히 작게 나타난다.
Gradient Boosting Regression
from sklearn.ensemble import GradientBoostingRegressor
# Gradient Boosting Regression
gbm = GradientBoostingRegressor(n_estimators=4000, alpha=0.01, random_state=42)
# 학습
gbm.fit(dataTrain_encoded, yLabelsLog)
# 예측 및 성능 평가
preds = gbm.predict(dataTrain_encoded)
print("RMSLE Value For Gradient Boost:", rmsle(yLabelsLog, preds, True))
RMSLE Value For Gradient Boost: 0.20673892878730882
RMSLE 값이 Random Forest Regression 모델보다 조금 더 크게 나타난다.
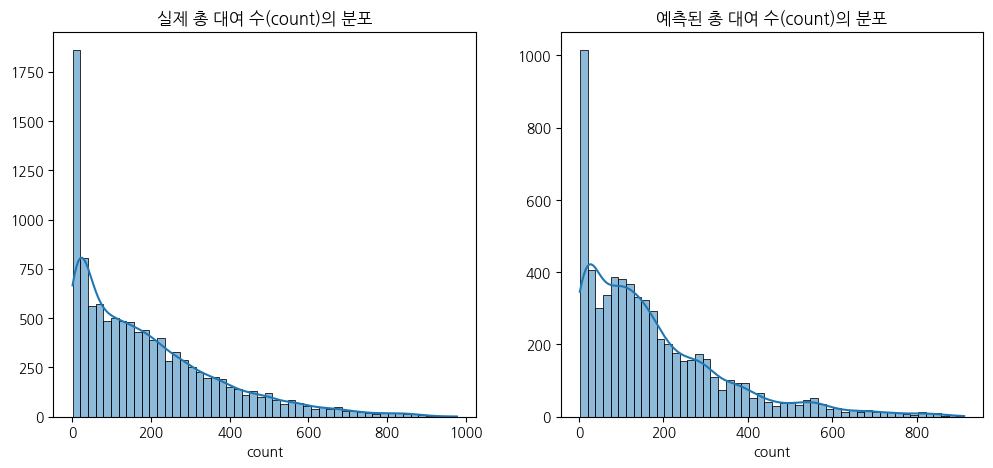
RFR 모델로 test 데이터 예측
RMSLE 값이 가장 작게 나온 Random Forest Regression 모델로 test 데이터를 예측해보았다.
# test 데이터에도 Dummy Encoding 적용
dataTest_encoded = pd.get_dummies(dataTest, drop_first=True)
# train 데이터와 test 데이터가 동일한 열을 가지도록 정렬
dataTest_encoded = dataTest_encoded.reindex(columns=dataTrain_encoded.columns, fill_value=0)
# test 데이터 예측 및 분포 시각화
predsTest = rfModel.predict(dataTest_encoded)
fig, (ax1, ax2) = plt.subplots(ncols=2)
fig.set_size_inches(12, 5)
sns.histplot(yLabels, ax=ax1, bins=50, kde=True)
ax1.set(title="실제 총 대여 수(count)의 분포", ylabel='')
sns.histplot(np.exp(predsTest), ax=ax2, bins=50, kde=True)
ax2.set(title="예측된 총 대여 수(count)의 분포", xlabel='count', ylabel='')
plt.show()
Leave a comment