
머신러닝을 통한 자전거 대여 수요 예측: (1) EDA
자전거 대여 시스템 데이터를 이용해 자전거 대여 패턴을 분석하고, 대여 수요를 가장 잘 예측하는 모델을 찾아내고자 한다.
데이터는 Kaggle의 Bike Sharing Demand 대회 데이터를 이용했다.
데이터 불러오기 및 확인
# 데이터 불러오기
df_train = pd.read_csv('./src/train.csv')
df_test = pd.read_csv('./src/test.csv')
df_train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10886 entries, 0 to 10885
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 10886 non-null object
1 season 10886 non-null int64
2 holiday 10886 non-null int64
3 workingday 10886 non-null int64
4 weather 10886 non-null int64
5 temp 10886 non-null float64
6 atemp 10886 non-null float64
7 humidity 10886 non-null int64
8 windspeed 10886 non-null float64
9 casual 10886 non-null int64
10 registered 10886 non-null int64
11 count 10886 non-null int64
dtypes: float64(3), int64(8), object(1)
memory usage: 1020.7+ KB
df_test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6493 entries, 0 to 6492
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 6493 non-null object
1 season 6493 non-null int64
2 holiday 6493 non-null int64
3 workingday 6493 non-null int64
4 weather 6493 non-null int64
5 temp 6493 non-null float64
6 atemp 6493 non-null float64
7 humidity 6493 non-null int64
8 windspeed 6493 non-null float64
dtypes: float64(3), int64(5), object(1)
memory usage: 456.7+ KB
train 데이터와 test 데이터 모두 결측치가 존재하지 않는다.
datetime변수가 object(string) type으로 되어 있어 이를 datetime type으로 변환하고 파생변수들을 생성하였다.
datetime 변수 형변환 및 파생변수 생성
# string to datetime
df_train['datetime'] = pd.to_datetime(df_train['datetime'])
df_test['datetime'] = pd.to_datetime(df_test['datetime'])
# year, month, day, hour, weekday 컬럼 생성
df_train['year'] = df_train['datetime'].dt.year
df_train['month'] = df_train['datetime'].dt.month
df_train['day'] = df_train['datetime'].dt.day
df_train['hour'] = df_train['datetime'].dt.hour
df_train['weekday'] = df_train['datetime'].dt.day_name()
df_test['year'] = df_test['datetime'].dt.year
df_test['month'] = df_test['datetime'].dt.month
df_test['day'] = df_test['datetime'].dt.day
df_test['hour'] = df_test['datetime'].dt.hour
df_test['weekday'] = df_test['datetime'].dt.day_name()
df_train.head()
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | year | month | day | hour | weekday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 | 2011 | 1 | 1 | 0 | Saturday |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 | 2011 | 1 | 1 | 1 | Saturday |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 | 2011 | 1 | 1 | 2 | Saturday |
| 3 | 2011-01-01 03:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 3 | 10 | 13 | 2011 | 1 | 1 | 3 | Saturday |
| 4 | 2011-01-01 04:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 0 | 1 | 1 | 2011 | 1 | 1 | 4 | Saturday |
로그 변환
# train 데이터 변수들 히스토그램
# 사용할 변수 목록
columns_to_plot = [
"season", "holiday", "workingday", "weather",
"temp", "atemp", "humidity", "windspeed",
"casual", "registered", "count", "year"
]
def plot_selected_histograms(df, columns):
num_columns = len(columns)
rows = (num_columns + 3) // 4
plt.figure(figsize=(16, rows * 4))
for i, column in enumerate(columns, 1):
plt.subplot(rows, 4, i)
plt.hist(df[column], bins=30, color='blue', alpha=0.7, edgecolor='black')
plt.title(column)
plt.tight_layout()
plt.show()
plot_selected_histograms(df_train, columns_to_plot)
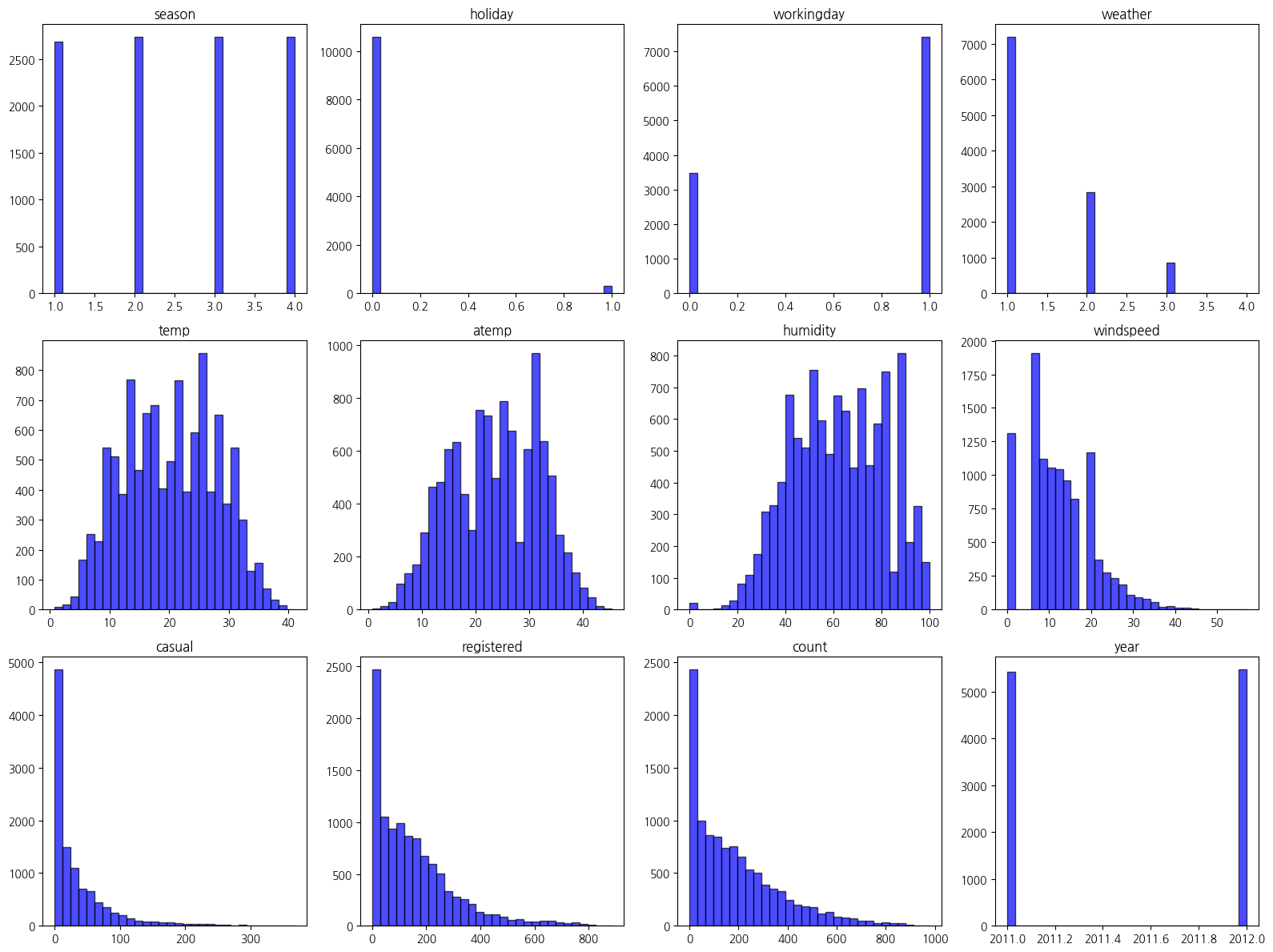
모델에서 종속변수로 사용될 casual, registered, count 변수의 데이터의 분포가 왼쪽으로 치우쳐져 있다.
따라서 로그 변환을 통해 데이터 정규화를 진행하였다.
# 로그 변환
def apply_log_transformation(df, columns):
for column in columns:
df[column] = np.log1p(df[column])
return df
columns_to_log_transform = ["casual", "registered", "count"]
df_train = apply_log_transformation(df_train, columns_to_log_transform)
columns_to_plot = ["casual", "registered", "count"]
plot_selected_histograms(df_train, columns_to_plot)
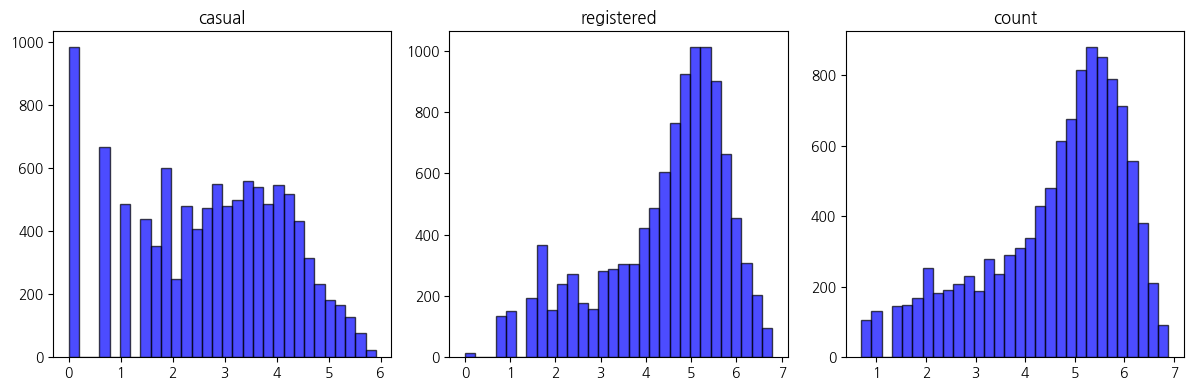
season 변수 재정의
# season별 casual, registered, count 박스플롯
def plot_boxplots_by_season_horizontal(df, variables, group_by_column):
num_variables = len(variables)
plt.figure(figsize=(18, 6))
for i, var in enumerate(variables, 1):
plt.subplot(1, num_variables, i)
grouped_data = [df[df[group_by_column] == season][var] for season in sorted(df[group_by_column].unique())]
plt.boxplot(
grouped_data,
tick_labels=sorted(df[group_by_column].unique()),
patch_artist=True,
boxprops=dict(facecolor='skyblue', color='blue'),
medianprops=dict(color='red'),
whiskerprops=dict(color='blue')
)
plt.title(f"{var} by {group_by_column}")
plt.xlabel(group_by_column.capitalize())
plt.ylabel(var.capitalize())
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
variables_to_plot = ["casual", "registered", "count"]
plot_boxplots_by_season_horizontal(df_train, variables_to_plot, "season")
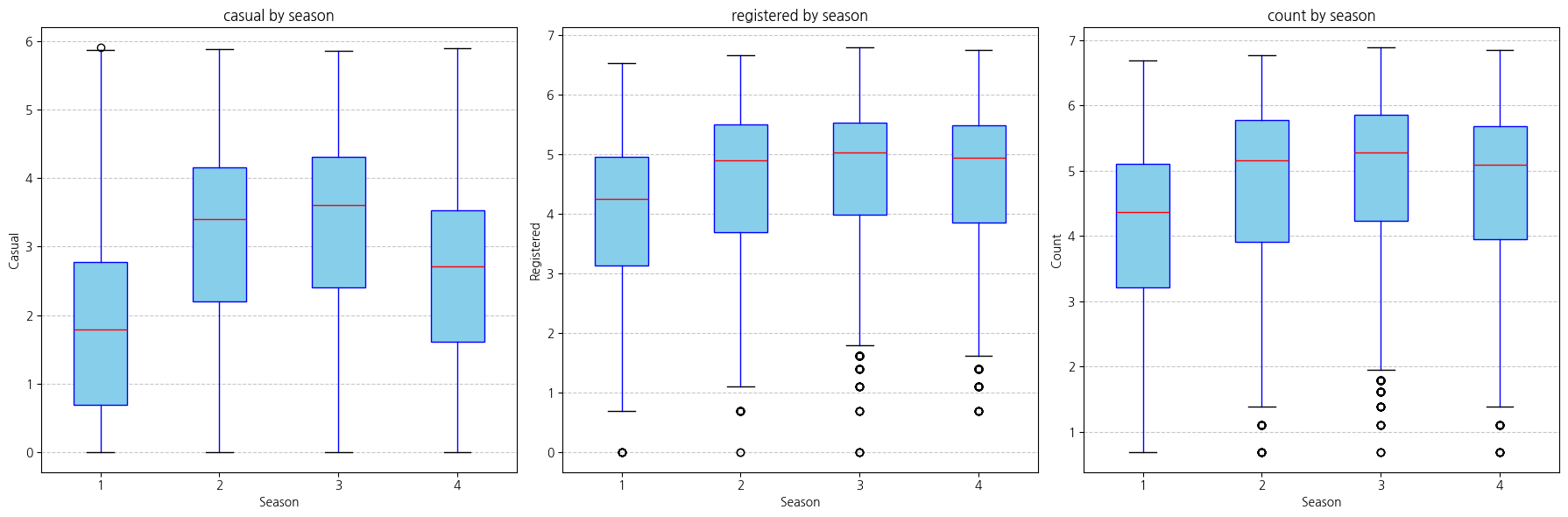
season 변수의 1이 봄이고 4가 겨울인데, 봄의 자전거 대여 수가 겨울보다 적게 나타나는 것에 대해 의문이 들었다.
# season이 1(봄)일 때 month
df_train[df_train['season'] == 1]['month'].unique()
array([1, 2, 3], dtype=int32)
# season이 4(겨울)일 때 month
df_train[df_train['season'] == 4]['month'].unique()
array([10, 11, 12], dtype=int32)
확인해보니 1월~3월이 season 변수의 1(봄)로 할당되어 있었고, 10월~12월이 season 변수의 4(겨울)로 할당되어 있었다.
보통 12월~2월을 겨울, 3월~5월을 봄으로 보기 때문에 season 변수를 재정의할 필요가 있는지 확인하기 위해 월별 온도를 시각화했다.
# 월별 평균 기온 시각화
month_avg_temp = df_train.groupby("month")["temp"].mean()
plt.figure(figsize=(10, 6))
plt.plot(month_avg_temp.index, month_avg_temp.values, marker='o', linestyle='-', color='blue')
plt.title("월별 평균 기온", fontsize=16)
plt.xlabel("월", fontsize=12)
plt.ylabel("기온", fontsize=12)
plt.xticks(month_avg_temp.index)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.show()
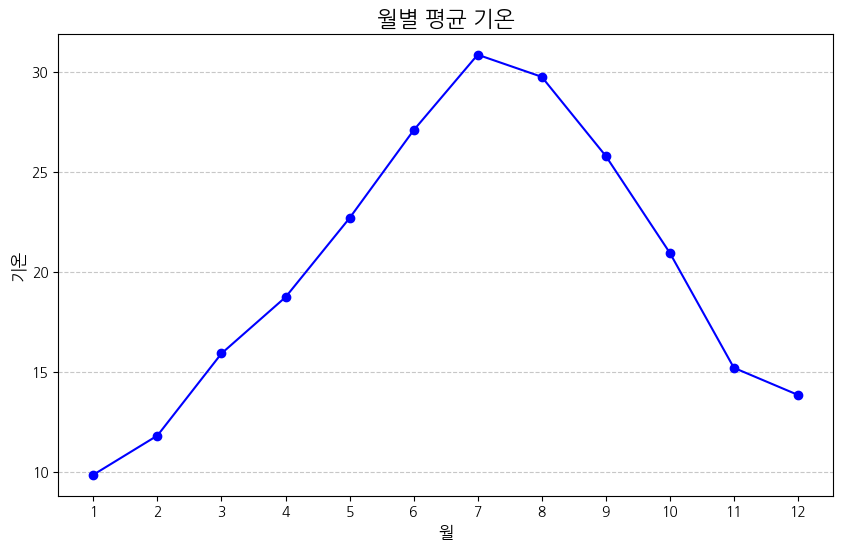
예상대로 12월~2월에 연중 온도가 가장 낮게 나타나
season변수를 재정의하였다.
# season 변수 재정의
conditions = [
df_train['month'].isin([3, 4, 5]),
df_train['month'].isin([6, 7, 8]),
df_train['month'].isin([9, 10, 11]),
df_train['month'].isin([12, 1, 2])
]
choices = [1, 2, 3, 4]
df_train['season'] = np.select(conditions, choices)
# season별 casual, registered, count 박스플롯
def plot_boxplots_by_season_horizontal(df, variables, group_by_column):
num_variables = len(variables)
plt.figure(figsize=(18, 6))
for i, var in enumerate(variables, 1):
plt.subplot(1, num_variables, i)
grouped_data = [df[df[group_by_column] == season][var] for season in sorted(df[group_by_column].unique())]
plt.boxplot(
grouped_data,
tick_labels=sorted(df[group_by_column].unique()),
patch_artist=True,
boxprops=dict(facecolor='skyblue', color='blue'),
medianprops=dict(color='red'),
whiskerprops=dict(color='blue')
)
plt.title(f"{var} by {group_by_column}")
plt.xlabel(group_by_column.capitalize())
plt.ylabel(var.capitalize())
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.show()
variables_to_plot = ["casual", "registered", "count"]
plot_boxplots_by_season_horizontal(df_train, variables_to_plot, "season")
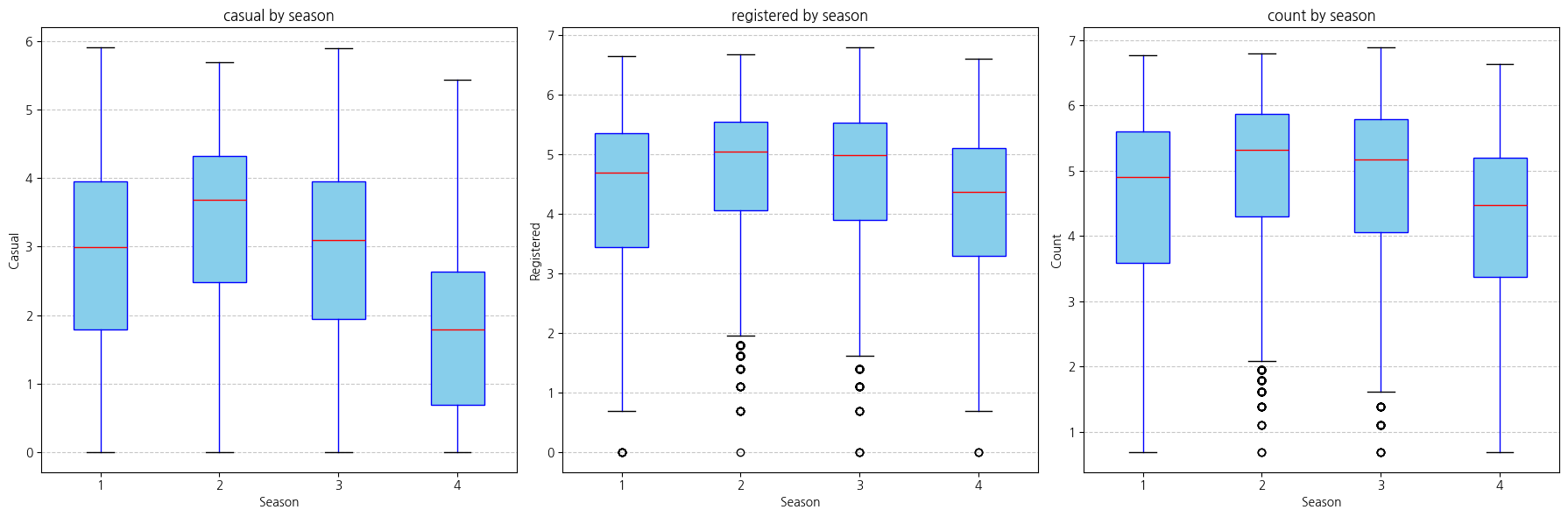
재정의 후 casual, registered, count 모두 겨울에 가장 적게 나타난다.
데이터 시각화
실제 값의 뚜렷한 추이를 보기 위해 시각화할 때는 로그 변환 전의 데이터를 사용하였다.
# 시각화를 위해 스케일링(로그 변환)되지 않은 train 데이터 준비
df_train_unscaled = pd.read_csv('./src/train.csv')
# string to datetime
df_train_unscaled['datetime'] = pd.to_datetime(df_train['datetime'])
# year, month, day, hour 컬럼 생성
df_train_unscaled['year'] = df_train_unscaled['datetime'].dt.year
df_train_unscaled['month'] = df_train_unscaled['datetime'].dt.month
df_train_unscaled['day'] = df_train_unscaled['datetime'].dt.day
df_train_unscaled['hour'] = df_train_unscaled['datetime'].dt.hour
df_train_unscaled['weekday'] = df_train_unscaled['datetime'].dt.day_name()
# season 변수 재정의
conditions = [
df_train_unscaled['month'].isin([3, 4, 5]),
df_train_unscaled['month'].isin([6, 7, 8]),
df_train_unscaled['month'].isin([9, 10, 11]),
df_train_unscaled['month'].isin([12, 1, 2])
]
choices = [1, 2, 3, 4]
df_train_unscaled['season'] = np.select(conditions, choices)
# 월별 평균 대여 수
monthly_avg = df_train_unscaled.groupby('month')['count'].mean()
plt.figure(figsize=(10, 5))
monthly_avg.plot(kind='bar', color='skyblue')
plt.title('월별 평균 대여 수')
plt.ylabel('평균 대여 수')
plt.xlabel('월')
plt.xticks(ticks=range(12), labels=range(1, 13), rotation=0)
plt.tight_layout()
plt.show()
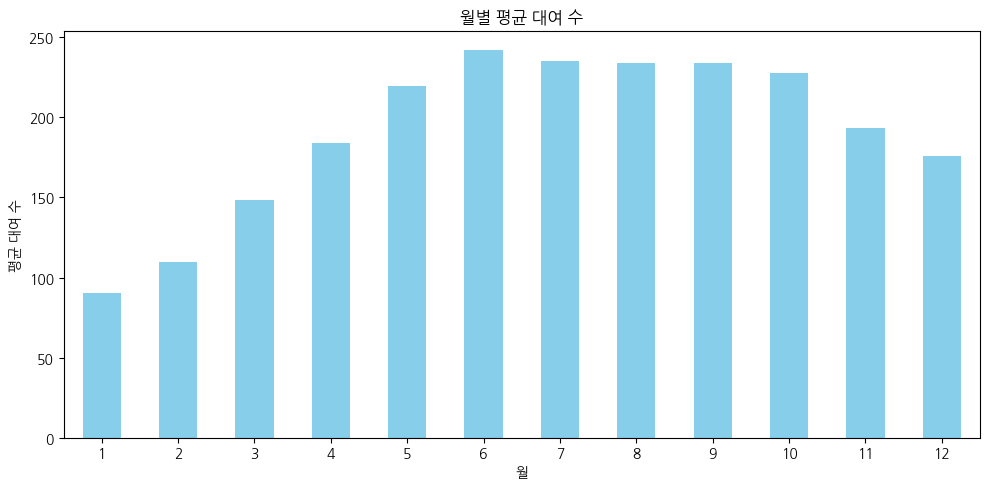
여름철에 자전거 대여 수가 증가하고 겨울철에 자전거 대여 수가 감소한다.
# 계절에 따른 시간대별 평균 대여 수
season_hour_avg = df_train_unscaled.groupby(['season', 'hour'])['count'].mean().reset_index()
season_map = {1: 'Spring', 2: 'Summer', 3: 'Fall', 4: 'Winter'}
season_hour_avg['season'] = season_hour_avg['season'].map(season_map)
plt.figure(figsize=(10, 5))
sns.lineplot(data=season_hour_avg, x='hour', y='count', hue='season', marker='o')
plt.title('계절에 따른 시간대별 평균 대여 수')
plt.ylabel('평균 대여 수')
plt.xlabel('시간대(하루)')
plt.xticks(range(0, 24))
plt.grid(axis='y')
plt.tight_layout()
plt.show()
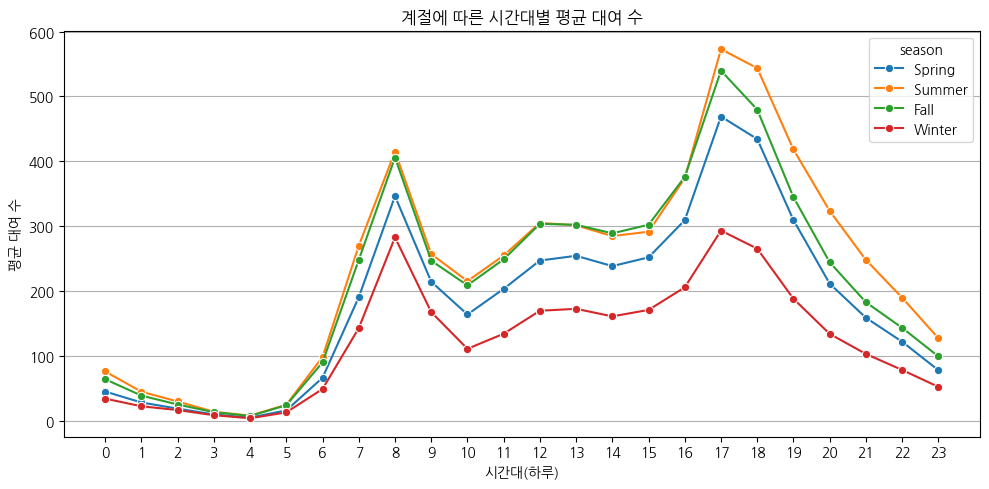
여름, 가을, 봄, 겨울 순으로 자전거 대여 수가 많다.
출퇴근 시간대에 자전거 대여 수가 급증한다.
# 요일에 따른 시간대별 평균 대여 수
weekday_hour_avg = df_train_unscaled.groupby(['weekday', 'hour'])['count'].mean().reset_index()
weekday_hour_avg['weekday'] = pd.Categorical(
weekday_hour_avg['weekday'],
categories=['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'],
ordered=True
)
plt.figure(figsize=(10, 5))
sns.lineplot(data=weekday_hour_avg, x='hour', y='count', hue='weekday', marker='o')
plt.title('요일에 따른 시간대별 평균 대여 수')
plt.ylabel('평균 대여 수')
plt.xlabel('시간대(하루)')
plt.xticks(range(0, 24))
plt.grid(axis='y')
plt.tight_layout()
plt.show()
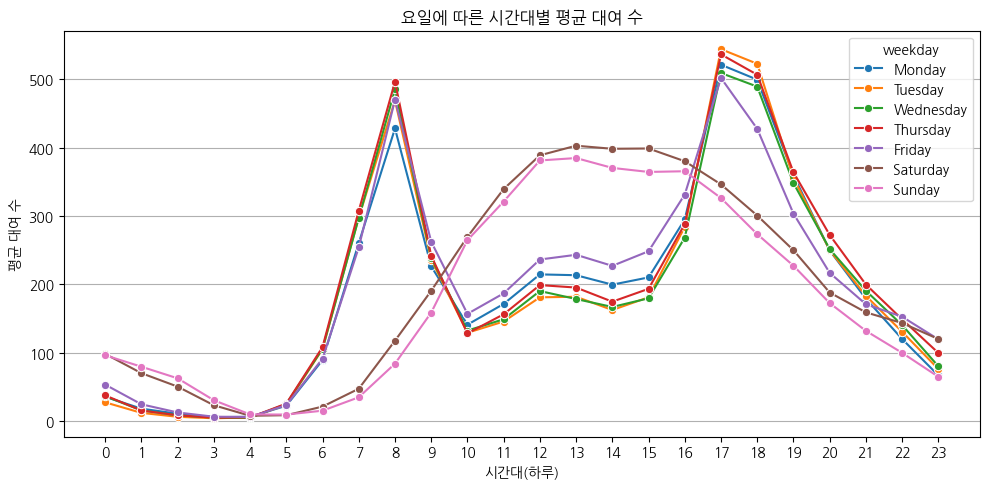
평일에는 출퇴근 시간대에 자전거 대여 수가 급증하고, 주말에는 오후 시간대에 자전거 대여 수가 많게 유지된다.
평일에는 실용적으로, 주말에는 여가용으로 대여가 많이 발생한다고 볼 수 있다.
# 사용자 타입에 따른 시간대별 평균 대여 수
user_type_hour_avg = df_train_unscaled.groupby(['hour']).agg({'casual': 'mean', 'registered': 'mean'}).reset_index()
plt.figure(figsize=(10, 5))
sns.lineplot(data=user_type_hour_avg, x='hour', y='casual', label='Casual', marker='o')
sns.lineplot(data=user_type_hour_avg, x='hour', y='registered', label='Registered', marker='o')
plt.title('사용자 타입에 따른 시간대별 평균 대여 수')
plt.ylabel('평균 대여 수')
plt.xlabel('시간대(하루)')
plt.xticks(range(0, 24))
plt.legend(title='User Type')
plt.grid(axis='y')
plt.tight_layout()
plt.show()
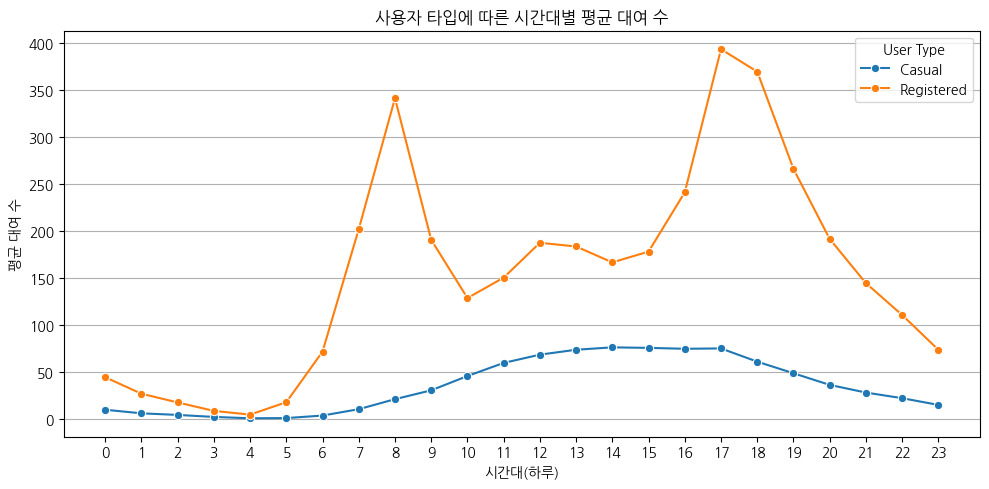
주로 등록 사용자는 출퇴근 용도로, 미등록 사용자는 여가 용도로 자전거를 대여함을 알 수 있다.
등록 사용자의 대여 수가 미등록 사용자의 대여 수보다 많은 것도 볼 수 있다.
Leave a comment