
High-dimensional clustering 문제 해결 방법
군집 분석을 위해 데이터 간의 유사도를 계산한다.
이때 feature의 수가 너무 많다면(예: 100개 이상), 여러 문제점이 생긴다.
1. 차원의 저주 문제
차원의 저주: 학습 데이터의 수가 차원의 수보다 적어 모델의 성능이 저하되는 현상
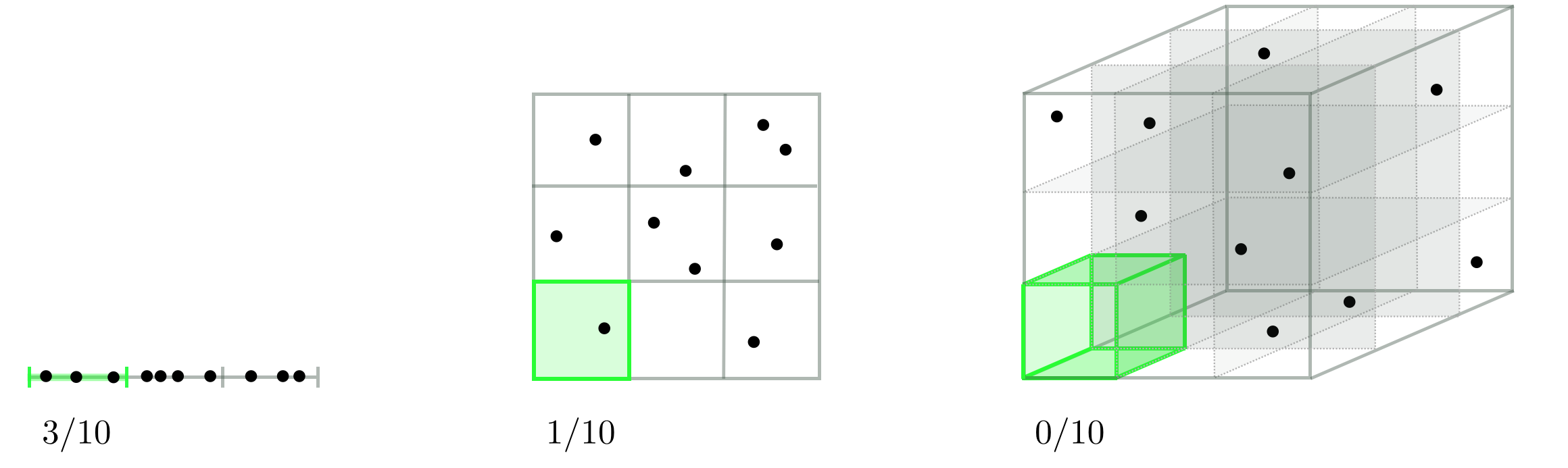
sample의 수보다 feature의 수가 많으면 sample들 사이에 빈 공간이 늘어나게 된다.
모델을 학습시킬 때 정보가 없는 공간이 많아지는 것이고, 이는 모델의 성능을 저하시킨다.
차원의 저주를 해결하는 방법으로는 첫째로 차원을 축소하는 방법이 있다.
기존의 feature들을 주요한 feature들로 압축하여 추출해 차원을 축소하는 것이다.
대표적인 방법으로 주성분 분석(PCA)가 있다.
주성분 분석은 데이터의 분산을 최대한 보존하면서 주요한 feature들을 추출한다.
차원의 저주를 해결하는 다른 방법으로는 중요한 feature만 선택하는 방법이 있다.
종속성이 강한 불필요한 feature는 제거하고, 데이터의 특징을 잘 나타내는 중요한 feature만 선택하는 것이다.
구체적인 방법으로 Filter Method, Wrapper Method, Embedded Method 등이 있다.
2. 데이터 분포의 복잡성
고차원 데이터는 종종 비선형적이고 복잡한 구조를 가진다.
비선형적으로 분포된 데이터는 전통적인 클러스터링 기법으로 군집화하기 어렵다.
이런 경우 DBSCAN과 같은 밀도 기반의 클러스터링 기법을 이용하는 것이 해결책이 될 수 있다.
3. 높은 계산 비용
고차원 데이터는 계산 비용이 많이 들며, 큰 데이터셋을 처리할 때 특히 문제가 된다.
비용을 줄이기 위해서는 단순한 클러스터링 알고리즘을 이용해 계산 효율성을 높일 수 있다.
단순한 클러스터링 알고리즘으로는 대표적으로 K-Means 클러스터링 알고리즘이 있다.
차원 축소 기법과 결합해 사용하면 더욱 효과적인 성능을 보일 수 있다.
Leave a comment